Null Hypothesis Significance Testing, part 1
 Image credit: Gerd Altmann from Pixabay
Image credit: Gerd Altmann from Pixabay1# r import
2library(tidyverse)
3library(knitr)
4library(reticulate)
5library(broom)
6
7options(digits = 4)
1# python import
2import pandas as pd
3from scipy import stats
1# custom functions
2nhst_result <- function(pval, alpha){
3 if(pval < alpha) {
4 print(paste0("p-value is less than alpha (",
5 alpha, "). Reject the null hypothesis."))
6 } else {print(paste0("p-value is greater than alpha (",
7 alpha, "). Fail to reject the null hypothesis."))}
8}
Introduction
The concept of hypothesis testing is analogous to the concept of criminal trials. Consider that you are a judge during a trial and there is a person for a criminal offense. You must decide if the defendant is innocent or guilty. Your basic knowledge is that the person is innocent and after evidence comes in you need to make a choice - is there enough evidence to claim that the defendant is guilty?

There are four possible outcomes:
| The defendant is innocent | The defendant is guilty | |
|---|---|---|
| You decide that the defendant is innocent | Correct decision | You set the criminal free |
| You decide that the defendant is guilty | You send the innocent person to jail | Correct decision |
If we transform this to “statistical language”, we would say that we have:
- Null hypothesis $H_0$, which tells us that defendant is innocent (nothing is happening).
- Alternative hypothesis $H_A$, which tells us that defendant is guilty (something is actually happening).
- Significance level $\alpha$, which is the probability of sending an innocent person to jail (probability of rejecting the null hypothesis $H_0$ when it is true). That is also called a Type I error.
The probability of setting the criminal free is usually denoted as $\beta$ (probability of accepting the null hypothesis $H_0$ when it is false). That is also called a Type II error
We can rewrite the previous table in the general form:
| $H_0$ is true | $H_0$ is false | |
|---|---|---|
| Failed to reject $H_0$ | No Error | Type II Error |
| Reject $H_0$ in favor of $H_A$ | Type I Error | No Error |
Sure you don’t want to send an innocent person to jail, but what level of significance $\alpha$ would you choose? Usually alpha is set up to 0.05, meaning that we let ourselves have a $5\%$ possibility chance of wrong decision. Other common values of alpha are $0.1, 0.01$. If we set a low threshold for $\alpha$ (for example 0.001), then it will require more evidence to convict an innocent person. On the other hand, if we set a higher threshold for $\alpha$ (for example 0.1), then less evidence is required.
In the statistical hypothesis testing framework we usually calculate the p-value* and check whether it is greater or less than a significance level $\alpha$.
The p-value is the probability of obtaining results as extreme as the observed results under the assumption that null hypothesis is true. To be able to reject the null hypothesis p-value needs to be lower than the significance level $\alpha$.
- $P(\text{Data | }H_0 \text{ is true}) \leq \alpha$: reject the null hypothesis in favor of the alternative hypothesis.
- $P(\text{Data | }H_0 \text{ is true}) > \alpha$: fail (not enough evidence) to reject the null hypothesis.
Steps for hypothesis testing:
- Formulate the null and alternative hypotheses.
- Choose a proper test for a given problem.
- Set the significance level $\alpha$.
- Calculate the desired statistic and p-value associated with it.
- Interpret the results in the context of a problem.
Note that the $4.$ point is highlighted. This is usually the only step that can be done by software (SPSS, R, Python, Excel, etc) meaning that the user must do all the work left: choose null and alternative hypothesis, decide what test to use, interpret the results.
Some examples of hypothesis would be:
| Null hypothesis $H_0$ | Alternative hypothesis $H_A$ |
|---|---|
| The coin is fair $\left( P(\text{Heads}) = P(\text{Tails}) = \frac{1}{2} \right)$ | The coin is biased towards Heads $\left(P(\text{Heads}) > \frac{1}{2} \right)$ |
| The ratio of success for the new drug is 75% $\left(\pi = 0.75 \right)$ | A drug is more effective than previous version $\left(\pi>0.75 \right)$ |
| There is no difference in the average of blood pressure between two groups $\left(\mu_1 - \mu_2 = 0 \right)$ | Average blood pressure among two groups is different $\left(\mu_1 - \mu_2 \neq 0 \right)$ |
Note that significance testing checks the population parameters, not sample statistics, that’s why we use Greek letters.
Difference between population and sample:
One of the main purposes of statistics is to estimate the population parameter based on the sample statistic. For example, you would like to know what is the effect of the new drug for the subjects who have a specific disease ($\pi$ - the proportion of success). Performing an experiment on a whole population (every subject who has a disease) would give you a true ratio $\pi$ when the drug was effective vs. when it was not. However, performing such experiment would be extremely expensive and often not possible to perform. What you could do instead is to get a sample from your population (some number of subjects with a given disease), perform an experiment of them, and then generalize the results to the whole population based on the point estimate $p$ and confidence interval.

Intuitive Example
Let’s take a look at a simple example to build an intuition about p-value and alpha.
Imagine you have a coin and you are not sure if it’s fair or not. You flip the coin once and it comes up Heads. Would you assume that the coin is unfair (is it more likely to get Heads, rather than Tails)?
What about two Heads out of two flips? Three? Four? Five?
- 🥮, Probability = 0.5
- 🥮🥮, Probability = 0.25
- 🥮🥮🥮, Probability = 0.125
- 🥮🥮🥮🥮, Probability = 0.0625
- 🥮🥮🥮🥮🥮, Probability = 0.0313
Most people would doubt the fairness of the coin after five Heads out of five coin flips. If we calculate the probability of 5 Heads in a row we get:
$$P(\text{5 Heads}) = \left( \frac{1}{2} \right) ^ 5 = 0.0313$$In other words, there is about 3% of getting five Heads in a row assuming that the coin is fair. This seems to be a really low probability to be true, that is why most people would assume that this coin is not fair, but rather the probability of Heads $p(\text{Heads}) > \frac{1}{2}$.
If we have used NHST framework it would look as follows:
- $H_0$: coin is fair, $p(\text{Heads}) = \frac{1}{2}$
- $H_A$: coin is unfair, $p(\text{Heads}) > \frac{1}{2}$
- $\alpha = 0.05$
We flipped the coin 5 times and got 5 heads. Now, assuming that the coin is fair we calculate the probability of this event (which was 0.0313). Note that we used $p=\frac{1}{2}$ in the formula since we assume that coin is fair (null hypothesis is true). This probability of 0.0313 is our p-value. $\text{p-value} < \alpha$, that is why we reject the null hypothesis, saying that data provides enough evidence that coin is nor fair and the probability of Heads is greater than $\frac{1}{2}$.
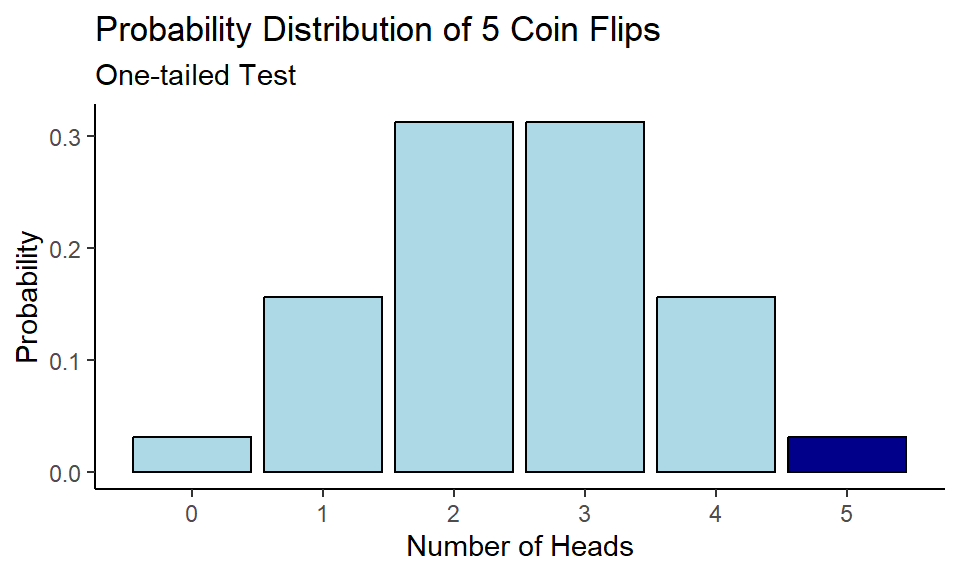
One-tailed vs Two-tailed Test
Our alternative hypothesis in this example was that the coin is unfair and $p(\text{Heads}) > \frac{1}{2}$, which is also called a one-tailed significance test. In such case we are interested only in probabilities of obtaining results more extreme as 5 out of 5 Heads. Due to the experiment design there was no outcome that was more extreme as 5 out of 5 Heads (since we couldn’t get 6 Heads out of 5 coin flips).
Another type of test would be two-tailed significance test. In this way we would be interested in probabilities of obtaining results more or as extreme as obtained data. The alternative hypothesis would be:
- $H_A$: the coin is unfair, $p(\text{Heads}) \neq \frac{1}{2}$ ($p(\text{Heads}) < \frac{1}{2}$ or $p(\text{Heads}) > \frac{1}{2}$)
As you can see, under the two-tailed testing we are not concerned about the direction of alternative hypothesis.
In our example outcome of 0 Heads (5 Tails) out of 5 flips has the same probability as observed probability of 5 Heads out of 5 flips. Hence,
$$\scriptsize \text{p-value} = P(0) + P(5) = 0.0313 + 0.0313 = 0.0616$$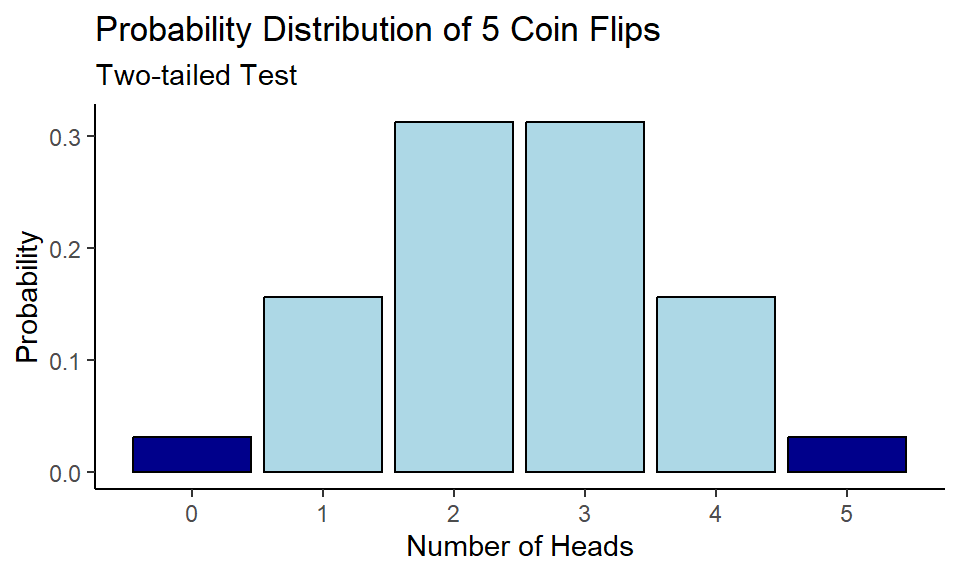
Since now $\text{p-value} > \alpha$ we would fail to reject the null hypothesis saying there is not enough evidence to claim that the coin is not fair.
Inference for a mean
In this section we are going to look at a significance testing for the population mean. The general formula looks as following:
$$\scriptsize \text{Statistic} = \frac{\text{Point Estimate} - \text{Null Value}}{\text{SE}}$$- Point Estimate - the data we have observed (one sample mean, a difference in two means, etc)
- Null Value - the value under the null hypothesis
- SE - standard error of the sample, $SE = \frac{s}{\sqrt{n}}$
- Statistic - the calculated value of a simulated distribution ($t$ distribution, $Z$ distribution, etc)
After we have calculated the statistic we can find the p-value (with the help of tables, R/Python).
Data Set
For this tutorial, we are going to look at Memory Test on Drugged Islanders Data data set from Kaggle1.
Context of the problem:
An experiment on the effects of anti-anxiety medicine on memory recall when being primed with happy or sad memories. The participants were done on novel Islanders whom mimic real-life humans in response to external factors. Participants were above 25+ years old to ensure a fully developed pre-frontal cortex, a region responsible for higher level cognition and memory recall.
| Drugs of interest (known-as) [Dosage 1, 2, 3]: | |
| `A` - Alprazolam (Xanax, Long-term) [1mg/3mg/5mg] |  |
| `T` - Triazolam (Halcion, Short-term) [0.25mg/0.5mg/0.75mg] |  |
| `S` - Sugar Tablet (Placebo) [1 tab/2tabs/3tabs] |  |
Mem_Score_Before and Mem_Score_After features show how long it took to finish a memory test before/after drug exposure (in seconds).
1islander_data <- read_csv("memory-test-on-drugged-islanders-data/Islander_data.csv")
2sample_n(islander_data, 5) %>% kable()
| first_name | last_name | age | Happy_Sad_group | Dosage | Drug | Mem_Score_Before | Mem_Score_After | Diff |
| Kaito | McCarthy | 51 | S | 1 | A | 48.3 | 44.6 | -3.7 |
| Ren | Carrasco | 25 | S | 2 | T | 78.8 | 84.5 | 5.7 |
| Eva | Carrasco | 34 | H | 3 | S | 45.0 | 46.2 | 1.2 |
| Michael | Lopez | 33 | H | 3 | S | 36.3 | 40.3 | 4.0 |
| Grace | Kennedy | 26 | H | 1 | A | 85.6 | 84.3 | -1.3 |
One Sample Test
The $t$-distribution2 is useful for describing the distribution of the sample mean when the population standard deviation $\sigma$ is unknown (which is almost always). That’s why this test is also called the One Sample $t$-Test3.
As the name of the test suggests, we are going to look at a single mean and whether it’s significantly different from the null value.
However, in order to perform $t$-test couple of conditions need to be met:
- Independence: sampled observations need to be independent (for example, it would be a bad idea to include relatives like parents-children for a Memory Test experiment, since results can be affected by inheritance).
- Randomness: the probability of occurrence of each observation in a sample is equally likely (for example, it the population of interest is islanders, men and women should have equal chances to be added to the experiment).
- Approximate Normality.
Also, the test may be affected by extreme values (outliers) that are better to be removed.
Example
Let’s assume that previous studies suggest that the average time to finish a memory test after 1mg of Alprazolam is 60 seconds. We have observed new data and we want to check if there is enough evidence to claim that the average time to finish a memory test is actually <60 seconds.
- $H_0$: Average time to finish a memory test after 1mg of Alprazolam is 60 seconds, $\mu = 60$
- $H_A$: Average time to finish a memory test after 1mg of Alprazolam is less than 60 seconds, $\mu < 60$
- $\alpha = 0.05$
1temp_df <- islander_data %>%
2 filter(Drug == "A" & Dosage == 1)
3
4hist(temp_df$Mem_Score_After,
5 main = "Distribution of Memory Test Results\nafter 1mg of Alprazolam",
6 xlab = "Average time to finish a memory test")
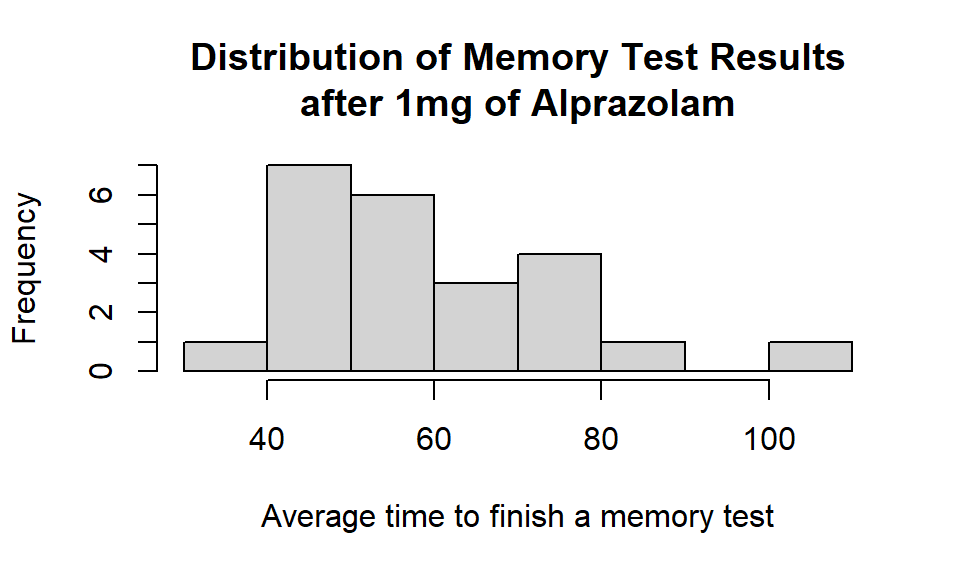
Summary statistics:
1temp_df %>%
2 summarise(mean = mean(Mem_Score_After),
3 std = sd(Mem_Score_After),
4 n = n()) %>%
5 kable()
| mean | std | n |
|---|---|---|
| 58.56 | 16.27 | 23 |
Using formula from above we can calculate point estimate (average value of the set), null estimate (60 seconds) and standard error.
1alpha <- 0.05
2null_estimate <- 60
3n <- length(temp_df$Mem_Score_After)
4x_bar <- mean(temp_df$Mem_Score_After)
5SE <- sd(temp_df$Mem_Score_After) / sqrt(n)
6
7t_stat <- (x_bar - null_estimate) / SE
8t_stat
1## [1] -0.4255
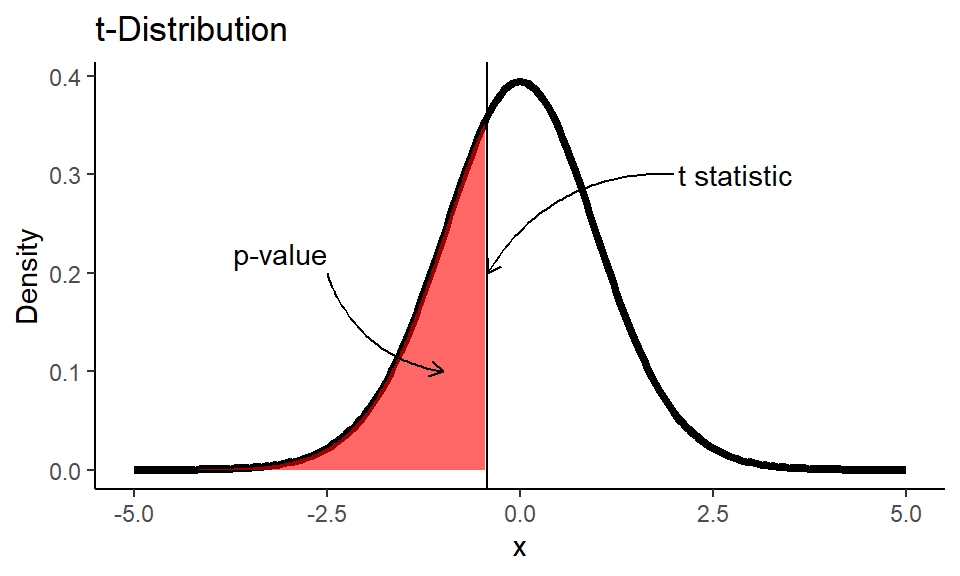
After we calculated $t$ statistic we can find the area under the $t$ distribution curve from $-\infty$ to $t_{\text{calc}}$. $t$ distribution has only one parameter - degrees of freedom, that are equal $df = n-1$, where $n$ is the sample size.
Code
1df <- n-1
2x <- seq(-5,5,0.05)
3t_dist <- dt(x, df)
4
5ggplot() +
6 geom_line(
7 mapping = aes(x = x, y = t_dist),
8 color = "black", size = 1.5) +
9 geom_vline(xintercept = t_stat) +
10 geom_area(
11 mapping = aes(x = x[x <= t_stat], y = t_dist[x <= t_stat]),
12 fill="red", alpha=0.6) +
13 labs(title = "t-Distribution",
14 y = "Density") +
15 annotate(
16 geom = "curve", x = 2, y = 0.3, xend = t_stat, yend = 0.2,
17 curvature = .3, arrow = arrow(length = unit(2, "mm"))) +
18 annotate(geom = "text", x = 2.05, y = 0.3, label = "t statistic", hjust = "left") +
19 annotate(
20 geom = "curve", x = -2.5, y = 0.2, xend = -1, yend = 0.1,
21 curvature = .3, arrow = arrow(length = unit(2, "mm"))) +
22 annotate(geom = "text", x = -2.5, y = 0.22, label = "p-value", hjust = "top") +
23 theme_classic()
1pval <- pt(t_stat, df)
2print(paste0("p-value is: ", round(pval, 3)))
3## [1] "p-value is: 0.337"
4alpha <- 0.05
5nhst_result(pval, alpha)
6## [1] "p-value is greater than alpha (0.05). Fail to reject the null hypothesis."
But would you still be able to get the conclusion of the test without software, if you did all the calculations by hand? The answer is “definitely yes”. When you have calculated $t_\text{stat}$ (which was -0.4255 in our example) you could compare this value to $t_\text{critical}$. $t_\text{critical}$ is the $\alpha$ (for one-tailed test) or $\alpha/2$ (for two-tailed test) quantile of $t$-distribution, that can be easily found in any of t-tables.
We need to find a value of $t_\text{critical}$ creates an area of 0.05 (our $\alpha$ level) under the curve for a $t$ distribution with 22 degrees of freedom:

1(t_crit <- qt(alpha, df))
1## [1] -1.717
Code
1df <- n-1
2x <- seq(-5,5,0.05)
3t_dist <- dt(x, df)
4
5ggplot() +
6 geom_line(
7 mapping = aes(x = x, y = t_dist),
8 color = "black", size = 1.5) +
9 geom_vline(xintercept = t_stat) +
10 geom_vline(xintercept = t_crit, color = "red") +
11 labs(title = "t-Distribution",
12 y = "Density") +
13 annotate(
14 geom = "curve", x = 2, y = 0.3, xend = t_stat, yend = 0.2,
15 curvature = .3, arrow = arrow(length = unit(2, "mm"))) +
16 annotate(geom = "text", x = 2.05, y = 0.3, label = "t statistic", hjust = "left") +
17 annotate(
18 geom = "curve", x = -4, y = 0.3, xend = t_crit, yend = 0.2,
19 curvature = .3, arrow = arrow(length = unit(2, "mm"))) +
20 annotate(geom = "text", x = -4.05, y = 0.3, label = "t ctitical", hjust = "right") +
21 geom_area(
22 mapping = aes(x = x[x <= t_stat], y = t_dist[x <= t_stat]),
23 fill="red", alpha=0.6) +
24 geom_area(
25 mapping = aes(x = x[x <= t_crit], y = t_dist[x <= t_crit]),
26 fill="blue", alpha=0.6) +
27 theme_classic()
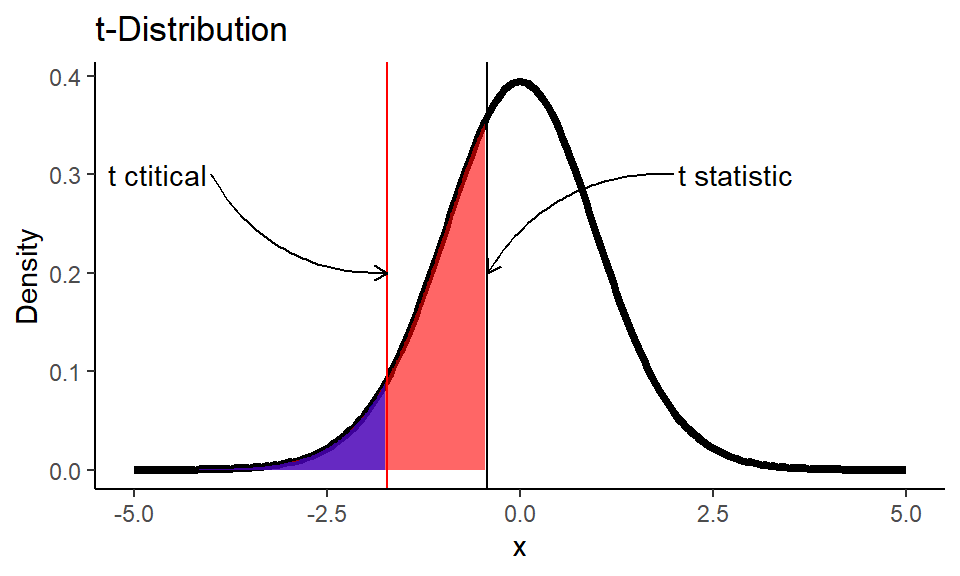
If out calculated $t$ statistic (black line) would be on the left side from critical $t$ value (red line) we would reject the null hypothesis, since we would be sure that the p-value (red area) is < 0.05. Here we see that our $t$ statistic is greater than $t_\text{critical}$, so we fail to reject the null hypothesis. It’s always a good idea to draw a test distribution.
Alternatively, we can let R and Python do all the calculations for us:
R
Built-in function t.test:
1t.test(temp_df$Mem_Score_After,
2 mu = 60,
3 conf.level = 0.95,
4 alternative = "less")
1##
2## One Sample t-test
3##
4## data: temp_df$Mem_Score_After
5## t = -0.43, df = 22, p-value = 0.3
6## alternative hypothesis: true mean is less than 60
7## 95 percent confidence interval:
8## -Inf 64.38
9## sample estimates:
10## mean of x
11## 58.56
Python
ttest_1samp function from scipy.stats module:
1islander_data = pd.read_csv("memory-test-on-drugged-islanders-data/Islander_data.csv")
2temp_df = islander_data[(islander_data["Drug"] == "A") & (islander_data["Dosage"] == 1)]
3
4t_stat, p_val = stats.ttest_1samp(a=temp_df['Mem_Score_After'], popmean=60)
5
6print(f"Calculated test statistic: {t_stat: .4f}\np-value: {p_val/2: .4f}")
1## Calculated test statistic: -0.4255
2## p-value: 0.3373
Note that ttest_1samp returns the result for two-sided test, that is why we need to divide the p-value by 2.
Two Sample Test (Independent Groups)
Now we are going to compare the mean values of two groups and check if there is a statistically significant difference between them. In the same way, to perform Two-Sample $t$-test the condition of independence needs to be met, meaning that you cannot compare the difference of a memory test result before and after the pill for the same person. Also, for the two sample $t$ test the variance of two groups need to be equal. There is a way4 to perform $t$-test when variances are not equal but it will not be covered here.
Example
Let’s check if there is a difference in memory test results after 5 mg of Alprazolam and 3 tabs of sugar pills (placebo).
- $H_0$: There is no difference in test results fare 5 mg of Alprazolam and 3 tabs of sugar pills, $\mu_{\text{Alprozam}} - \mu_{\text{Placebo}} = 0$
- $H_A$: There is a difference in test results fare 5 mg of Alprazolam and 3 tabs of sugar pills, $\mu_{\text{Alprozam}} - \mu_{\text{Placebo}} \neq 0$
- $\alpha = 0.05$
Code
1islander_data %>%
2 filter(Drug %in% c("A", "S") & Dosage == 3) %>%
3 group_by(Drug) %>%
4 ggplot() +
5 geom_boxplot(aes(x = Drug, y = Mem_Score_After, color = Drug), show.legend = FALSE) +
6 labs(title = "Distribution of Memory Test Result after Drugs",
7 y = "Memory Test Score") +
8 theme_classic()
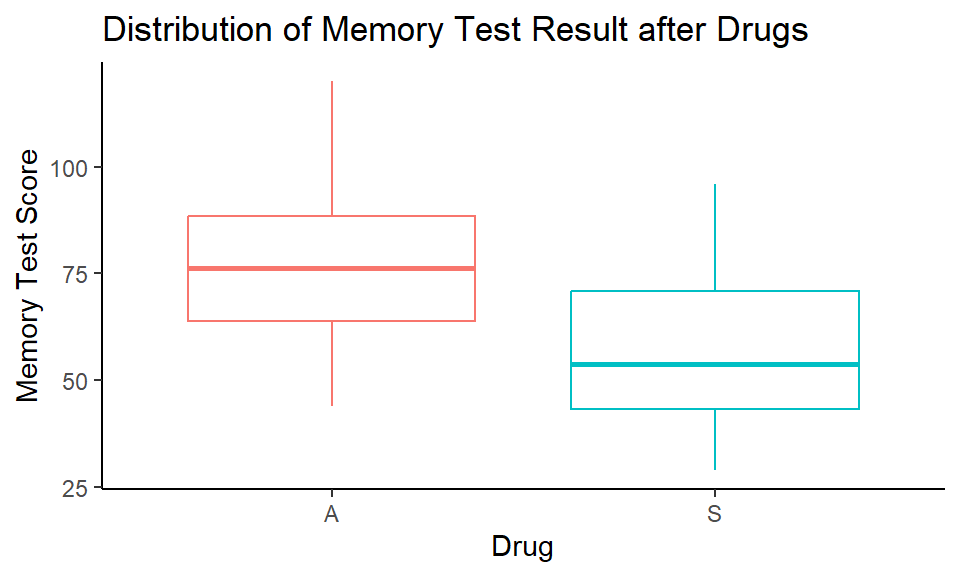
Summary statistics:
1islander_data %>%
2 filter(Drug %in% c("A", "S") & Dosage == 3) %>%
3 group_by(Drug) %>%
4 summarise(mean = mean(Mem_Score_After),
5 std = sd(Mem_Score_After),
6 n = n()) %>%
7 kable()
| Drug | mean | std | n |
|---|---|---|---|
| A | 77.54 | 18.94 | 22 |
| S | 57.60 | 18.40 | 22 |
Test statistic can be calculated in the same way:
$$\scriptsize t_{\text{calc}} = \frac{\text{Point Estimate} - \text{Null Estimate}}{SE}$$- Point estimate is the difference of two sample means: $\bar{x}_{\text{Alprozam}} - \bar{x}_{\text{Placebo}}$;
- Null estimate is the value under the null hypothesis: $\mu_{\text{Alprozam}} - \mu_{\text{Placebo}} = 0$
- “Pooled” standard error: $SE = \sqrt{\frac{s^2_\text{Alprazolam}}{n_\text{Alprazolam}} + \frac{s^2_\text{Placebo}}{n_\text{Placebo}}}$
- Degrees of freedom: $df = n_{\text{Alprozam}} + n_{\text{Placebo}} - 2$
1alp_sample <- islander_data %>%
2 filter(Drug == "A" & Dosage == 3) %>%
3 select(Mem_Score_After)
4pla_sample <- islander_data %>%
5 filter(Drug == "S" & Dosage == 3) %>%
6 select(Mem_Score_After)
7
8# sample means
9x_alp <- mean(alp_sample$Mem_Score_After)
10x_pla <- mean(pla_sample$Mem_Score_After)
11
12# sample variance
13var_alp <- var(alp_sample$Mem_Score_After)
14var_pla <- var(pla_sample$Mem_Score_After)
15
16# sample standard deviations
17s_alp <- sd(alp_sample$Mem_Score_After)
18s_pla <- sd(pla_sample$Mem_Score_After)
19
20# sample size
21n_alp <- length(alp_sample$Mem_Score_After)
22n_pla <- length(pla_sample$Mem_Score_After)
23
24# degrees of freedom
25df <- n_alp + n_pla - 2
Check that variances are equal:
For this purpose, we are going to use the proportion of two variances $\frac{s_1^2}{s_2^2}$ to estimate the proportion of population variances $\frac{\sigma_1^2}{\sigma_2^2}$ using $F$-distribution5.
- $H_0$: population variances are equal $\frac{\sigma_1^2}{\sigma_2^2} = 1$.
- $H_A$: population variances are different $\frac{\sigma_1^2}{\sigma_2^2} \neq 1$.
$F$-distribution has two parameters $df_1 = n_1 - 1$ and $df_2 = n_2 -1$, where $n_1$ and $n_2$ is the size of samples.
1# check for equal variances
2var_ratio <- var_alp / var_pla
3pval <- pf(var_ratio, n_alp-1, n_pla-1, lower.tail = FALSE) * 2
4print(paste0("p-value is: ", round(pval, 3)))
1## [1] "p-value is: 0.896"
p-value is 0.9 so we failed to reject the null hypothesis that population variances are equal.
R
Built-in function `var.test` to compare two variances:
1var.test(alp_sample$Mem_Score_After, pla_sample$Mem_Score_After)
1##
2## F test to compare two variances
3##
4## data: alp_sample$Mem_Score_After and pla_sample$Mem_Score_After
5## F = 1.1, num df = 21, denom df = 21, p-value = 0.9
6## alternative hypothesis: true ratio of variances is not equal to 1
7## 95 percent confidence interval:
8## 0.4399 2.5518
9## sample estimates:
10## ratio of variances
11## 1.059
Calculate $t$-statistic:
1se <- sqrt(s_alp^2/n_alp + s_pla^2/n_pla)
2t_stat <- (x_alp - x_pla - 0) / se
3t_stat
1## [1] 3.542
Code
1x <- seq(-5,5,0.01)
2t_dist <- dt(x, df)
3
4ggplot() +
5 geom_line(
6 mapping = aes(x = x, y = t_dist),
7 color = "black", size = 1.5) +
8 geom_vline(xintercept = t_stat) +
9 geom_vline(xintercept = -t_stat) +
10 geom_area(
11 mapping = aes(x = x[x <= -t_stat], y = t_dist[x <= -t_stat]),
12 fill="red", alpha=0.6) +
13 geom_area(
14 mapping = aes(x = x[x >= t_stat], y = t_dist[x >= t_stat]),
15 fill="red", alpha=0.6) +
16 labs(title = "t-Distribution",
17 y = "Density") +
18 theme_classic()
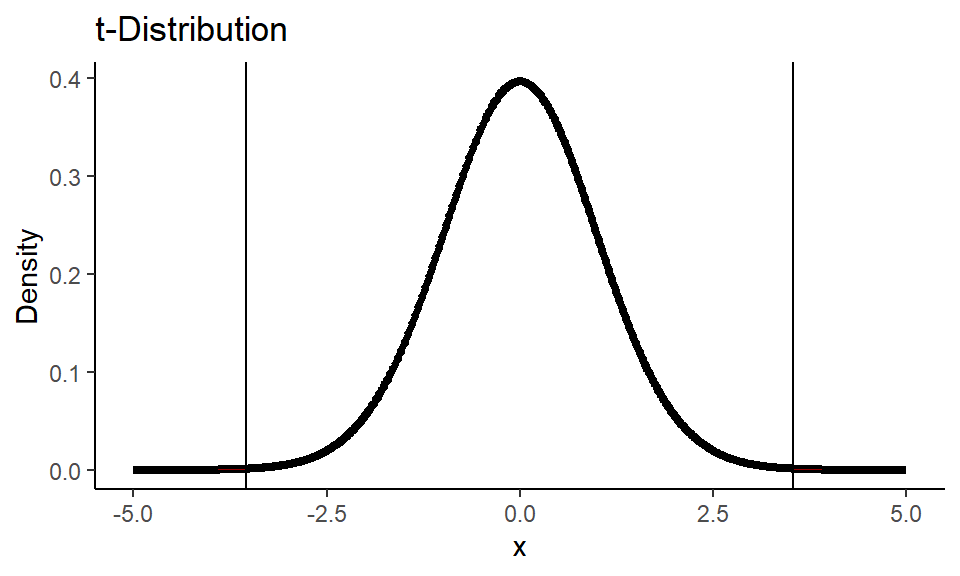
1pval <- pt(-t_stat, df)*2
2print(paste0("p-value is: ", round(pval, 3)))
3## [1] "p-value is: 0.001"
4alpha <- 0.05
5nhst_result(pval, alpha)
6## [1] "p-value is less than alpha (0.05). Reject the null hypothesis."
R
1t.test(alp_sample$Mem_Score_After,
2 pla_sample$Mem_Score_After,
3 null_estimate = 0,
4 conf.level = 0.95,
5 alternative = "two.sided",
6 var.equal = TRUE)
1##
2## Two Sample t-test
3##
4## data: alp_sample$Mem_Score_After and pla_sample$Mem_Score_After
5## t = 3.5, df = 42, p-value = 0.001
6## alternative hypothesis: true difference in means is not equal to 0
7## 95 percent confidence interval:
8## 8.58 31.30
9## sample estimates:
10## mean of x mean of y
11## 77.54 57.60
Python
ttest_ind function from stats module:
1alp_mask = (islander_data["Drug"] == "A") & (islander_data["Dosage"] == 3)
2pla_mask = (islander_data["Drug"] == "S") & (islander_data["Dosage"] == 3)
3
4alp_sample = islander_data["Mem_Score_After"][alp_mask]
5pla_sample = islander_data["Mem_Score_After"][pla_mask]
6
7t_stat, p_val = stats.ttest_ind(alp_sample, pla_sample, equal_var=True)
8
9print(f"Calculated test statistic: {t_stat: .4f}\np-value: {p_val: .5f}")
1## Calculated test statistic: 3.5422
2## p-value: 0.00099
Two Sample Test (Paired Groups)
But what if we still need to compare difference in dependent groups (for example before and after the drug)? We cannot use $t$-test for paired sample, however we can use a single sample $t$-test for a sample of differences.
Example
Let’s now check if there is a significant difference (in any direction, so two-tailed test) in memory test results before and after 0.75mg of Triazolam. Now we are going to use the variable Diff which was calculated as Mem_Score_After - Mem_Score_Before.
- $H_0$: There is no difference in test results before and after 0.75mg of Triazolam, $\mu_{\text{diff}} = 0$
- $H_A$: There is a difference in test results before and after 0.75mg of Triazolam, $\mu_{\text{diff}} \neq 0$
- $\alpha = 0.05$
1temp_df <- islander_data %>%
2 filter(Drug == "T" & Dosage == 3)
3
4hist(temp_df$Diff,
5 main = "Distribution of Difference of Memory Test Results\nbefore and after 0.75mg of Triazolam",
6 xlab = "Average time to finish a memory test")
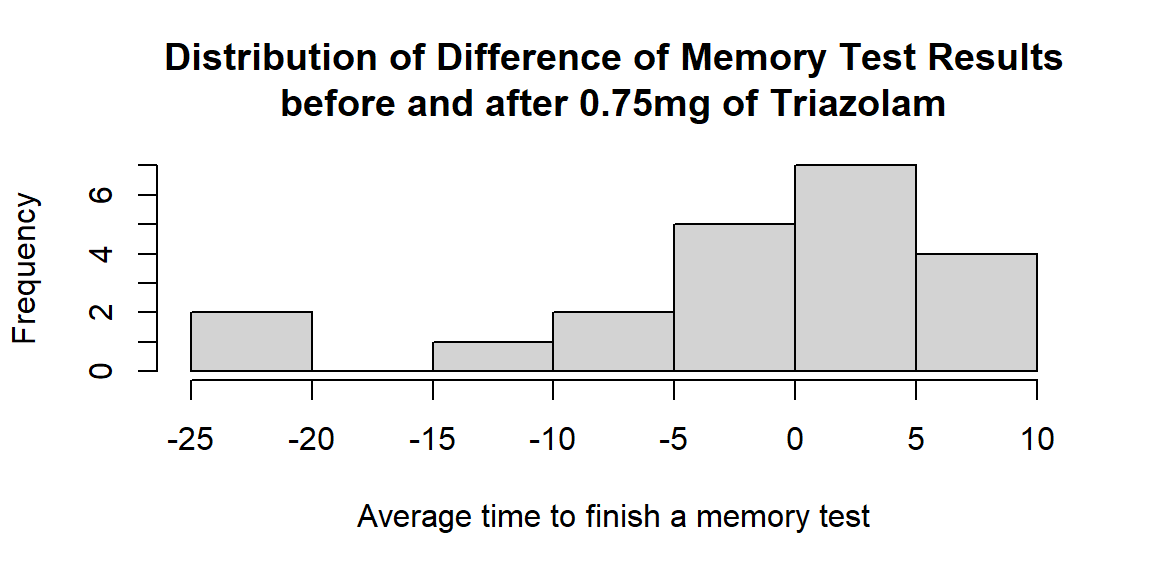
There are two outliers (difference in test results is less than $-20$) that need to be removed for further analysis:
1temp_df[temp_df$Diff < -20, ] %>% kable()
| first_name | last_name | age | Happy_Sad_group | Dosage | Drug | Mem_Score_Before | Mem_Score_After | Diff |
| Noemie | Kennedy | 73 | H | 3 | T | 110.0 | 87.8 | -22.2 |
| Naoto | Lopez | 39 | H | 3 | T | 50.8 | 30.4 | -20.4 |
Summary statistics:
1temp_df %>%
2 filter(Diff > -20) %>%
3 summarise(n = n(),
4 mean = mean(Diff),
5 std = sd(Diff)) %>%
6 kable()
| n | mean | std |
|---|---|---|
| 19 | 0.3368 | 6.186 |
R
1results <- t.test(temp_df$Diff[temp_df$Diff > -20],
2 mu = 0,
3 conf.level = 0.95,
4 alternative = "two.sided")
5
6results
1##
2## One Sample t-test
3##
4## data: temp_df$Diff[temp_df$Diff > -20]
5## t = 0.24, df = 18, p-value = 0.8
6## alternative hypothesis: true mean is not equal to 0
7## 95 percent confidence interval:
8## -2.644 3.318
9## sample estimates:
10## mean of x
11## 0.3368
Python
1temp_df = islander_data[(islander_data["Drug"] == "T") & (islander_data["Dosage"] == 3)]
2temp_df = temp_df[temp_df["Diff"] > -20]
3
4t_stat, p_val = stats.ttest_1samp(a=temp_df['Diff'], popmean=0)
5
6print(f"Calculated test statistic: {t_stat: .4f}\np-value: {p_val: .4f}")
1## Calculated test statistic: 0.2374
2## p-value: 0.8150
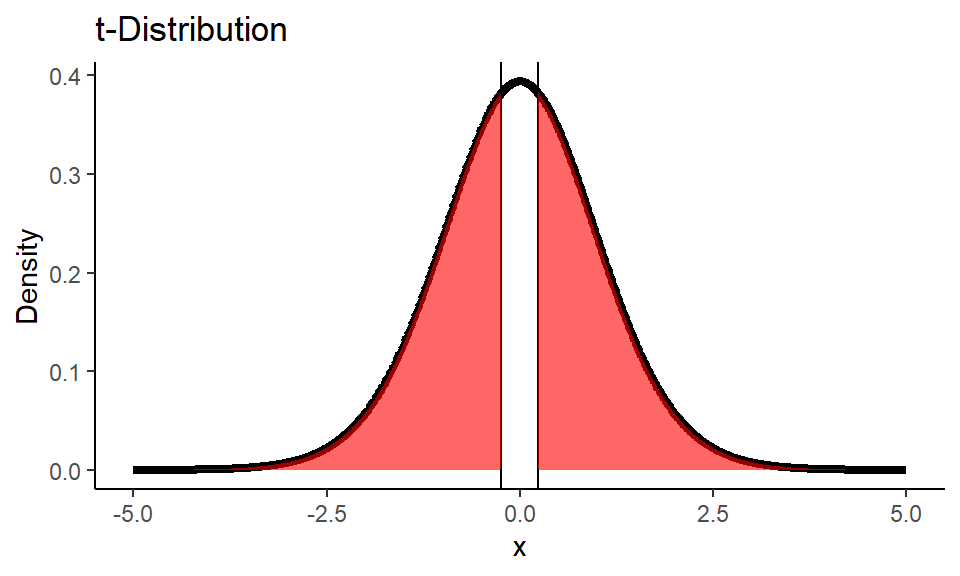
Since it’s two-tailed test we are interested in area under the curve from two sides of the distribution:
Code
1n <- dim(temp_df)[1]
2t_stat <- results$statistic
3df <- n-1
4x <- seq(-5,5,0.01)
5t_dist <- dt(x, df)
6
7ggplot() +
8 geom_line(
9 mapping = aes(x = x, y = t_dist),
10 color = "black", size = 1.5) +
11 geom_vline(xintercept = t_stat) +
12 geom_vline(xintercept = -t_stat) +
13 geom_area(
14 mapping = aes(x = x[x <= -t_stat], y = t_dist[x <= -t_stat]),
15 fill="red", alpha=0.6) +
16 geom_area(
17 mapping = aes(x = x[x >= t_stat], y = t_dist[x >= t_stat]),
18 fill="red", alpha=0.6) +
19 labs(title = "t-Distribution",
20 y = "Density") +
21 theme_classic()
Comparing More than Two Means (ANOVA)
Imagine that you want to compare the difference between the means in three or more samples. There is no way to do this using $t$-test, however, it can be done using ANOVA (ANalysis Of VAriance) and $F$ statistic. In the general form the hypothesis for ANOVA are described as:
- $H_0$: there is no difference among the group means, $\mu_1=\mu_2=...=\mu_k$
- $H_A$: at least two groups are significantly different (but it doesn’t specify which pair exactly).
- $k$ - the number of groups.
Test statistic $F$ can be calculated as:
$$F_\text{calc} = \frac{\text{Variability between groups}}{\text{Variability within groups}}$$Conditions that need to be met for ANOVA:
- Within Group Independence: sampled observations must be independent.
- Between Group Independence: non-paired groups.
- Approximate Normality.
- Equal Variance among groups.
Example
Let’s look for simplicity at the small number of samples and check whether there is a significant difference in memory test results before and after 0.25mg (Dosage = 1), 0.5mg (Dosage = 2) and 0.75mg (Dosage = 3) of Triazolam (3 samples in total).
Code
1islander_data %>%
2 filter(Drug == "T") %>%
3 ggplot() +
4 geom_boxplot(aes(x = as.factor(Dosage), y = Diff, color = as.factor(Dosage)),
5 show.legend = FALSE) +
6 labs(title = "Distribution of Difference in Memory Test Result\nbefore and after Triazolam",
7 y = "Memory Test Score",
8 x = "Dosage") +
9 theme_classic()
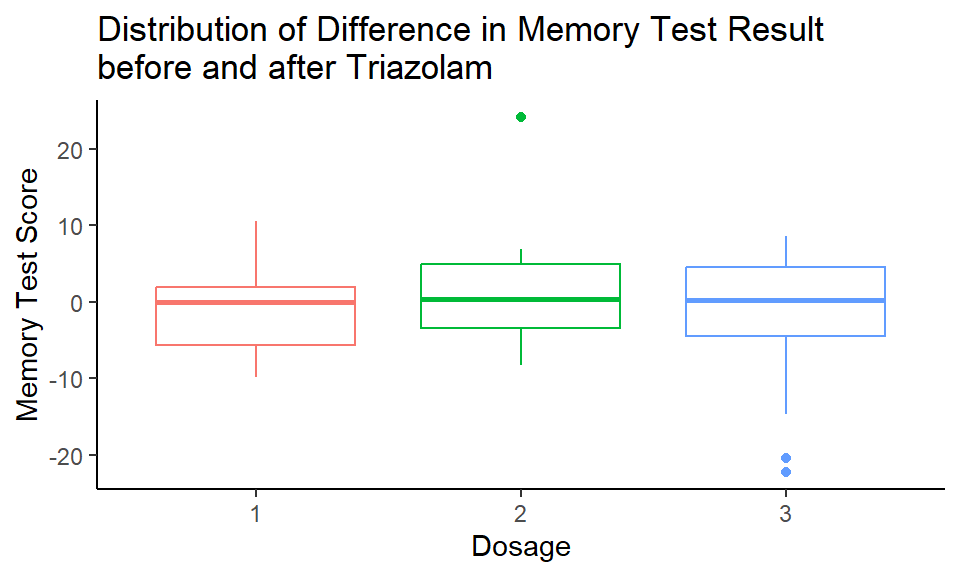
There are some outliers that need to be removed for further analysis:
1islander_data %>%
2 filter(Drug == "T" & (Diff < -15 | Diff > 15)) %>%
3 kable()
| first_name | last_name | age | Happy_Sad_group | Dosage | Drug | Mem_Score_Before | Mem_Score_After | Diff |
| Naoto | Lopez | 35 | H | 2 | T | 33.4 | 57.5 | 24.1 |
| Noemie | Kennedy | 73 | H | 3 | T | 110.0 | 87.8 | -22.2 |
| Naoto | Lopez | 39 | H | 3 | T | 50.8 | 30.4 | -20.4 |
Summary statistics:
1islander_data %>%
2 filter(Drug == "T" & Diff > -15 & Diff < 15) %>%
3 group_by(Dosage) %>%
4 summarise(mean = mean(Diff),
5 std = sd(Diff),
6 n = n()) %>%
7 kable()
| Dosage | mean | std | n |
|---|---|---|---|
| 1 | -1.2409 | 5.530 | 22 |
| 2 | 0.0571 | 4.450 | 21 |
| 3 | 0.3368 | 6.186 | 19 |
1temp_df <- islander_data %>%
2 filter(Drug == "T" & Diff > -15 & Diff < 15)
3
4oned_sample <- temp_df$Diff[temp_df$Dosage == 1]
5twod_sample <- temp_df$Diff[temp_df$Dosage == 2]
6threed_sample <- temp_df$Diff[temp_df$Dosage == 3]
**Check for equal variances**
1# check for equal variances
2var.test(oned_sample, twod_sample)
3##
4## F test to compare two variances
5##
6## data: oned_sample and twod_sample
7## F = 1.5, num df = 21, denom df = 20, p-value = 0.3
8## alternative hypothesis: true ratio of variances is not equal to 1
9## 95 percent confidence interval:
10## 0.6309 3.7454
11## sample estimates:
12## ratio of variances
13## 1.545
14var.test(oned_sample, threed_sample)
15##
16## F test to compare two variances
17##
18## data: oned_sample and threed_sample
19## F = 0.8, num df = 21, denom df = 18, p-value = 0.6
20## alternative hypothesis: true ratio of variances is not equal to 1
21## 95 percent confidence interval:
22## 0.3143 1.9678
23## sample estimates:
24## ratio of variances
25## 0.7993
26var.test(twod_sample, threed_sample)
27##
28## F test to compare two variances
29##
30## data: twod_sample and threed_sample
31## F = 0.52, num df = 20, denom df = 18, p-value = 0.2
32## alternative hypothesis: true ratio of variances is not equal to 1
33## 95 percent confidence interval:
34## 0.2022 1.2944
35## sample estimates:
36## ratio of variances
37## 0.5175
Condition is met.
Total variability ($SST$, sum of squares total) in the memory test results can be divided into variability attributed to the drug (between group variability) and variability attributed to other factors (within group variability).
$$SST = SSG + SSE$$$$SST = \sum_{i=1}^n \left[ (y_i - \bar{y})^2 \right]$$- $\bar{y}$: total average value.
$SSG$: the sum of squares for groups, measures the variability between groups. Explained variability.
$$SSG = \sum_{j=1}^k \left[ n_j (\bar{y_j} - \bar{y})^2 \right]$$- $n_j$: number of samples in $j$ group.
- $\bar{y_j}$: average value for the $j$ group.
$SSE$: the sum of squares for error, measures the variability within groups. Unexplained variability.
We can rewrite the formula for $F$ statistic:
$$F = \frac{MSG}{MSE}$$$MSG$: Mean Squares for groups. Average variability between groups calculated as the total variability (sum of squares) scaled by degrees of freedom.
$$MSG = \frac{SSG}{df_{\text{group}}}$$$MSE$ Mean Squares for error. Average variability within groups calculated as the total variability (sum of squares) scaled by degrees of freedom.
$$MSE = \frac{SSE}{df_{\text{Error}}}$$Degrees of freedom can be found as:
- $df_{\text{total}} = n - 1$
- $df_{\text{group}} = k -1$
- $df_{\text{error}} = df_{\text{total}} - df_{\text{group}}$
1# calculations
2
3# degrees of freedom
4n <- dim(temp_df)[1]
5k <- length(unique(temp_df$Dosage))
6df_total <- n - 1
7df_group <- k - 1
8df_error <- df_total - df_group
9
10# sum of squares
11y_bar <- mean(temp_df$Diff)
12(sst <- sum((temp_df$Diff - y_bar)^2))
13## [1] 1757
14
15(temp_df %>%
16 group_by(Dosage) %>%
17 summarise(n = n(),
18 yj_bar = mean(Diff)) %>%
19 mutate(ssg = n * (yj_bar - y_bar)^2) %>%
20 summarise(sum(ssg)) %>%
21 as.numeric() -> ssg)
22## [1] 29.84
23
24(sse <- sst - ssg)
25## [1] 1727
26
27# average variability
28(msg <- ssg / df_group)
29## [1] 14.92
30(mse <- sse / df_error)
31## [1] 29.27
32
33F_stat <- msg / mse
34print(paste0("Calculated F statistic: ", round(F_stat, 3)))
35## [1] "Calculated F statistic: 0.51"
Code
1x <- seq(0,4,0.01)
2f_dist <- df(x, df_group, df_error)
3
4ggplot() +
5 geom_line(
6 mapping = aes(x = x, y = f_dist),
7 color = "black", size = 1.5) +
8 geom_vline(xintercept = F_stat) +
9 geom_area(
10 mapping = aes(x = x[x >= F_stat], y = f_dist[x >= F_stat]),
11 fill="red", alpha=0.6) +
12 labs(title = "F-Distribution",
13 y = "Density") +
14 theme_classic()
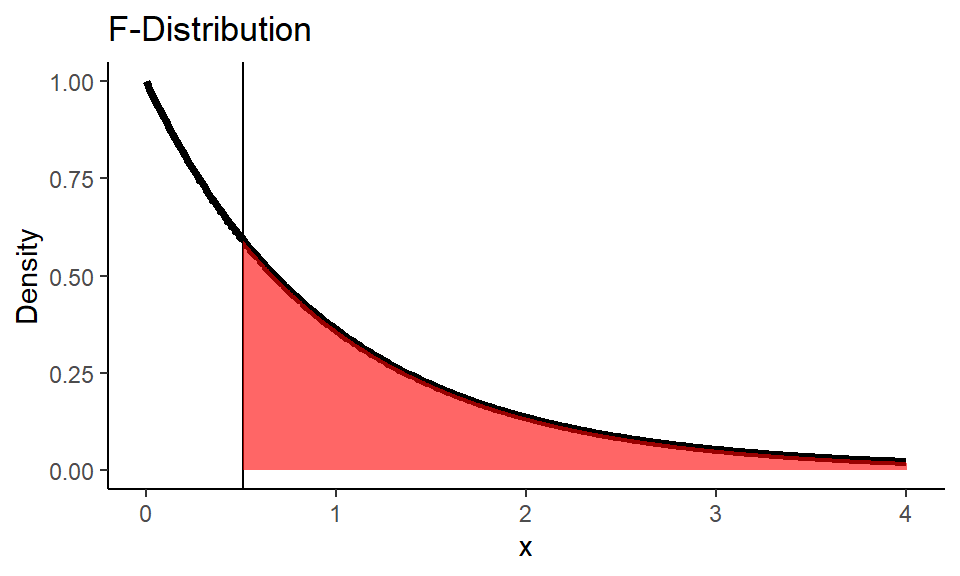
1pval <- pf(F_stat, df_group, df_error, lower.tail = FALSE)
2print(paste0("p-value is: ", round(pval, 3)))
3## [1] "p-value is: 0.603"
4alpha <- 0.05
5nhst_result(pval, alpha)
6## [1] "p-value is greater than alpha (0.05). Fail to reject the null hypothesis."
As you can see there is a lot of calculations, so most of the time we rely on software:
R
Built-int `aov` function:
1aov(formula = Diff ~ as.factor(Dosage),
2 data = temp_df) %>%
3 tidy() %>%
4 kable()
| term | df | sumsq | meansq | statistic | p.value |
|---|---|---|---|---|---|
| as.factor(Dosage) | 2 | 29.84 | 14.92 | 0.5098 | 0.6033 |
| Residuals | 59 | 1726.89 | 29.27 | NA | NA |
Python
`f_oneway` function from `stats` module:
1temp_df = islander_data[(islander_data["Drug"] == "T") & (islander_data["Diff"].between(-15, 15))]
2F_stat, p_val = stats.f_oneway(
3 temp_df["Diff"][temp_df["Dosage"] == 1],
4 temp_df["Diff"][temp_df["Dosage"] == 2],
5 temp_df["Diff"][temp_df["Dosage"] == 3])
6
7print(f"Calculated test statistic: {F_stat: .4f}\np-value: {p_val: .4f}")
1## Calculated test statistic: 0.5098
2## p-value: 0.6033
Summary
I hope that you have a better understanding of algorithms for inference for a population means after this tutorial. As you could see, calculation of p-value can be easily done by R/Python, however, there is lots of work for us before and after the calculations. We always need to choose the right test, check conditions for this test, and interpret the results in the context of the problem, etc. Also, making decisions based only on p-value isn’t always enough, and also we need to take into account an effect size, that will be described in a later tutorial.